Copyright © 2007-2018 Russ Dewey

Visual Scene Analysis: The Emergence of Cognitive Science
As we saw in previous chapters, computers helped stimulate the modern interest in cognition. That word covers knowledge, awareness, and mental processes in general.
Computers influenced cognitive psychologists in at least three ways. (1) Computers provided a new perspective by portraying intelligence as information processing. (2) Computers provided a tool for doing research, for example, by displaying stimuli, collecting responses, and analyzing data. (3) Computers provided a new way of testing theories through simulations: imitations of mental processes in computer programs.
At the dawn of the computer age, in the 1950s and early 1960s, researchers identified two different ways to studying cognitive processes using computers. Artificial intelligence (AI) researchers, typically headquartered in computer science departments, tried to make computers act intelligent without regard to how humans did it.
The concern of an AI researcher was creating a program that worked (acted with intelligence). If humans did things differently, AI researchers did not care.
Contrasting with AI was the approach of cognitive psychology. This approach, typically headquartered in a psychology department, tried to explain how humans performed acts of cognition. Computer techniques were not necessarily relevant.
What was the classic distinction between the AI and cognitive approaches?
By the mid-1970s the two groups realized they could benefit by learning from each other. The term cognitive science came into use, as a way of covering all research aimed at understanding cognition, much the way neuroscience is used to cover all research related to the nervous system.
Today, cognitive science researchers could be working in a department of linguistics, computer science, education, or psychology (among others). Research in cognitive neuroscience occurs at the overlap between cognitive science and neuroscience.
You will notice in this chapter frequent references to brain scans and other forms of biological evidence. Computer makers are learning from brain physiology, too, experimenting with techniques for modeling electronic circuits after brain circuits (so-called neuromorphic circuits).
Most cognitive science researchers today are problem oriented. They care about particular issues such as face recognition or auditory perception. Any helpful insights are welcomed, whether they come from artificial intelligence, cognitive psychology, neuroscience, or some other approach.
What is cognitive science like now?
Computer simulations (imitations of natural processes on a computer) provide a rigorous way to test a cognitive theory. The challenge to a theorist is clear: "If you think you have a good theory about how a cognitive process works, use it to design a computer program that accomplishes the task."
This is a tough challenge! It is also a big change from the pre-computer era, when speculations about mental processes were hard to prove or disprove. Computer programs either work or do not work; the results are clear.
Consider the work of the gestalt psychologists, mentioned in chapter 4. They offered demonstrations and principles and they speculated about energy fields in the brain, but they had no way to test their ideas in a more scientific way. All they had were examples and demonstrations.
In the work on visual scene analysis we will see some of the issues identified by the gestalt psychologists were tackled again. Computers were taught to find the boundaries of an object, identifying edges that pass behind another object, and much more.
The issues are the same ones raised by the gestalt psychologists. The difference is: this time, computers are able to show what techniques actually work, to perform these skills.
What are simulations and how do they provide a "tough challenge"?
We will start our survey of cognitive science by examining one of the most successful efforts to simulate a cognitive process: the classic work from the Massachusetts Institute of Technology (MIT) on visual scene analysis.
Visual Scene Analysis
Visual scene analysis is a prime example of artificial intelligence research influencing cognitive scientists' understanding of human cognitive processes. It was one of the earliest success stories in complex AI, encouraging researchers to explore similar solutions to other cognitive problems.
Visual scene analysis is a computer's version of visual perception. To analyze a visual scene, the computer must identify objects and relationships between objects, labeling each correctly.
For example, if provided with a robotic arm or graphic equivalent, a computer program must be able to manipulate objects in response to commands such as, "Place the triangular block on the long, thin block." These performances (labeling, answering questions, manipulating) serve as behavioral proof that the program "understands" a scene.
When do researchers say a computer "understands" a scene?
In classic 1960s work, a team at MIT (Massachusetts Institute of Technology) tried to teach a computer to recognize various arrangements of a simple block world. This world consisted of a computer representation of blocks on a table.
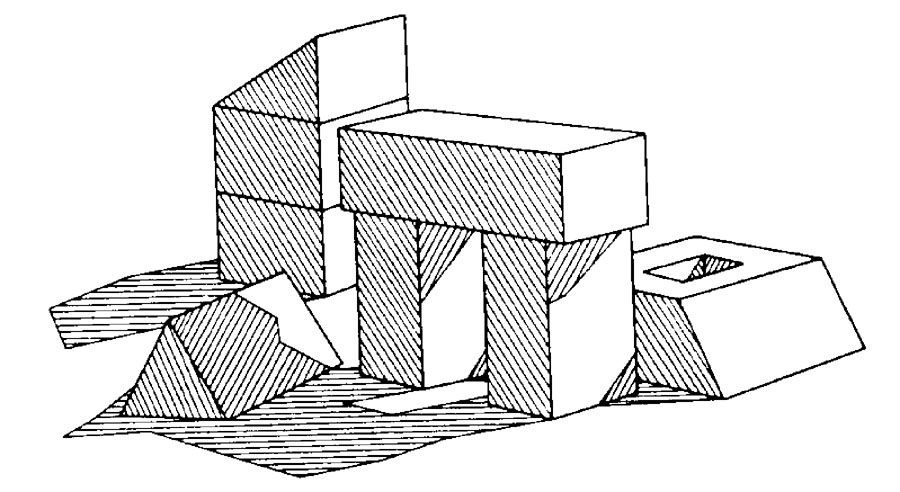
The MIT block world
To interpret the scene, the computer had to assign a meaning or interpretation to each line in the scene. For example, it had to know that one line represented the edge of a shadow, another represented the edge of a block facing the viewer, and so forth. The picture is said to be understood when every line is accurately labeled (Waltz, 1975).
What was the "block world"?
Initially researchers tried to ignore shadows, figuring they were an unnecessary complication to the task. However, it turned out that shadows provided important clues. Shadows helped to identify objects and relative positions of objects. So shadows were included in the block world.
Why did the program include shadows? What other features proved to be critically important?
The MIT team found lines, edges, and corners to be critical features of a visual scene. First the computer isolated lines and edges (areas of sudden contrast in the visual scene). Then the computer followed lines to corners where they intersected or bumped into other lines.
Each line segment could be interpreted 11 different ways (as an outer edge of an object, the edge of a shadow, and so forth). Before the computer could successfully interpret the scene, it had to pick one of the 11 meanings to assign to each line segment in the scene.
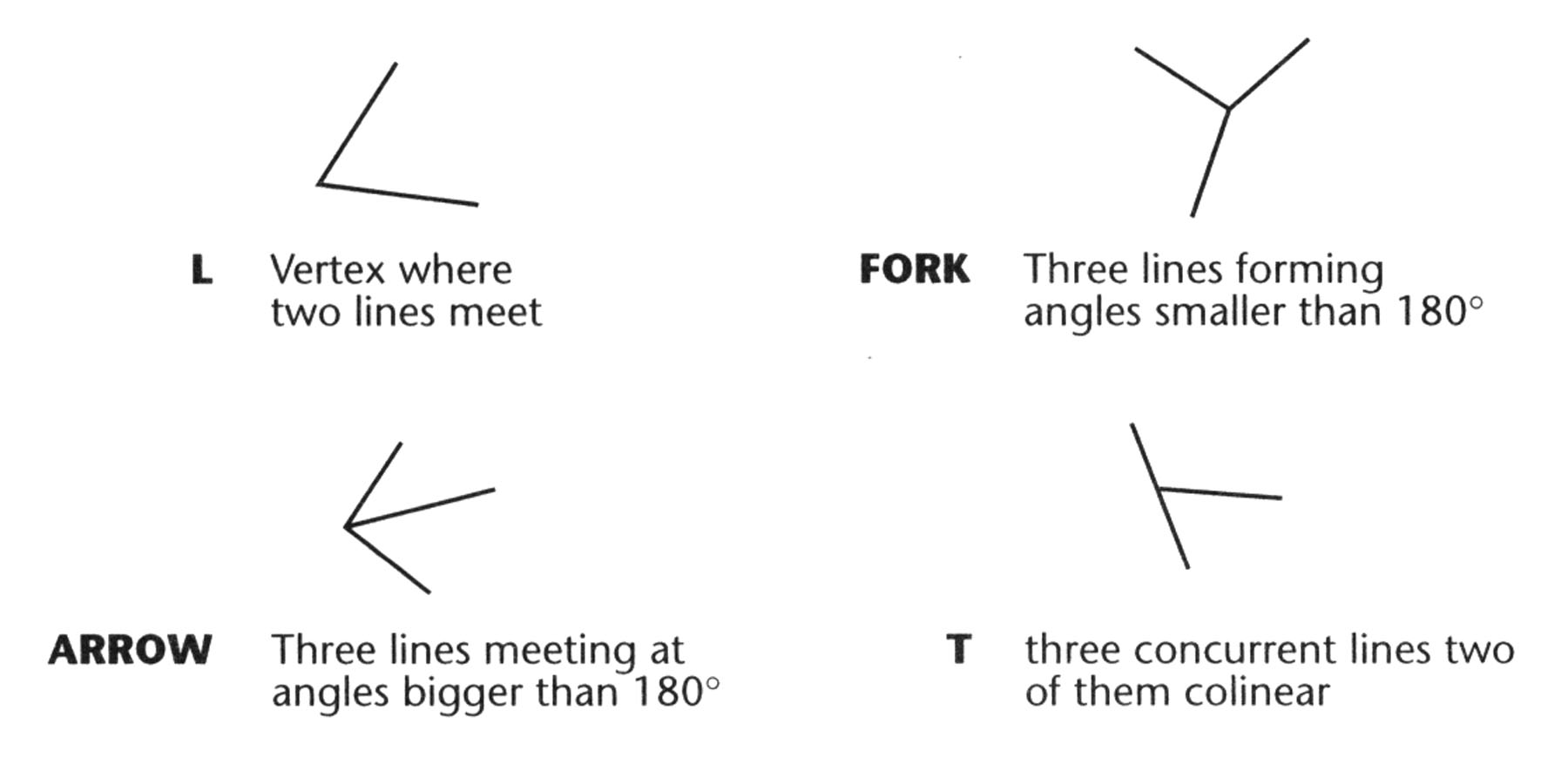
Four types of vertex identified by Guzman (1969)
Junctions of two or more lines are called vertexes (or vertices). Each vertex represents a corner of an object or a place where one object (or a shadow) cuts in front of another. The figure above shows four types of vertex identified by Guzman (1969).
What is an "arrow" vertex? A "fork"?
To interpret a visual scene, the computer has to assign a meaning to each vertex as well as each line segment. Consider the vertex called an arrow. In the following diagram are two arrows, each marked with a dot at its tip.
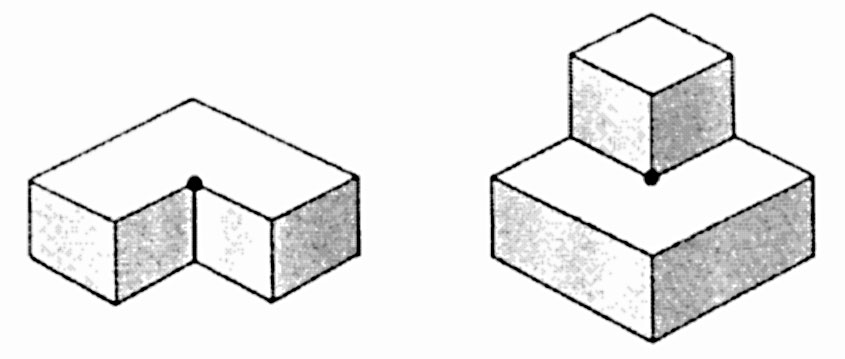
Upward and downward arrow vertices
An arrow can be an upward pointing inner corner (first diagram) or a downward pointing outer corner, (second diagram). But it cannot be both at once.
If the computer decides (based on other information such as shadows) that the arrow on the right is an outer edge of a small block sitting on a larger block, then the arrow can only be a downward pointing outer corner. Once the decision is made, this vertex is interpreted. That helps the computer interpret other parts of the scene.
Constraint Propagation
The assignment of meaning to one part of the scene limits the possible interpretations of other parts of the scene. This is called constraint satisfaction or constraint propagation.
It sounds complicated, but the basic idea is simple: the scene is interpreted by ruling out every interpretation except one. It is like a crime investigator eliminating every suspect except one, to find the guilty party.
Constraints propagate or spread because, once you limit the possible interpretation in one part of the scene, that limits or constrains the possible interpretation of other parts of the scene. Eventually only one interpretation of the whole scene is left. At that point, the scene is understood.
Upward and downward arrow vertices
For example, an arrow vertex might be tentatively interpreted as an upward pointing inner corner (like the figure on the left). That would mean the two line segments forming the point of the arrow must both be edges of an object.
That, in turn, means the point where they come together must be farther away than the edges leading to it. Once the program knows those things, it can make other assumptions, and on it goes until the entire scene is interpreted.
What is "constraint propagation" and how is it illustrated in these examples?
Again: the goal is to interpret the entire scene by assigning a specific meaning to each line segment. This is the upper edge of a block, that is the edge of a shadow, etc. Every corner and surface must be identified, too.
To rule out all interpretations of a scene except one is to "satisfy all the constraints" and understand the scene. Like a detective working on a murder case, the computer looks for the one interpretation that makes sense of all the evidence.
The MIT visual scene analysis program was one of the most successful examples of artificial intelligence research in the 20th Century. The project was largely successful by the mid-1980s.
Starting with just a few basic assumptions, computers could accept the input from a video camera and locate the boundaries of objects in any scene. The fundamental problem of gestalt formation or object segregation was solved for visual perception.
Constraint satisfaction is a basic process found in all sorts of cognitive processes, but it can be an elusive idea to students encountering it for the first time. For this reason, we will take a look at two examples that show how the brain assigns meaning to line segments and vertexes to understand diagrams.
The Necker Cube
Our first example involves a famous visual illusion, an ambiguous figure called the Necker Cube. It is one of the oldest visual illusions studied by psychologists, dating from the 1820s.
The line drawing of a cube can be interpreted more than one way. Psychologists call this an ambiguous or bi-stable figure.
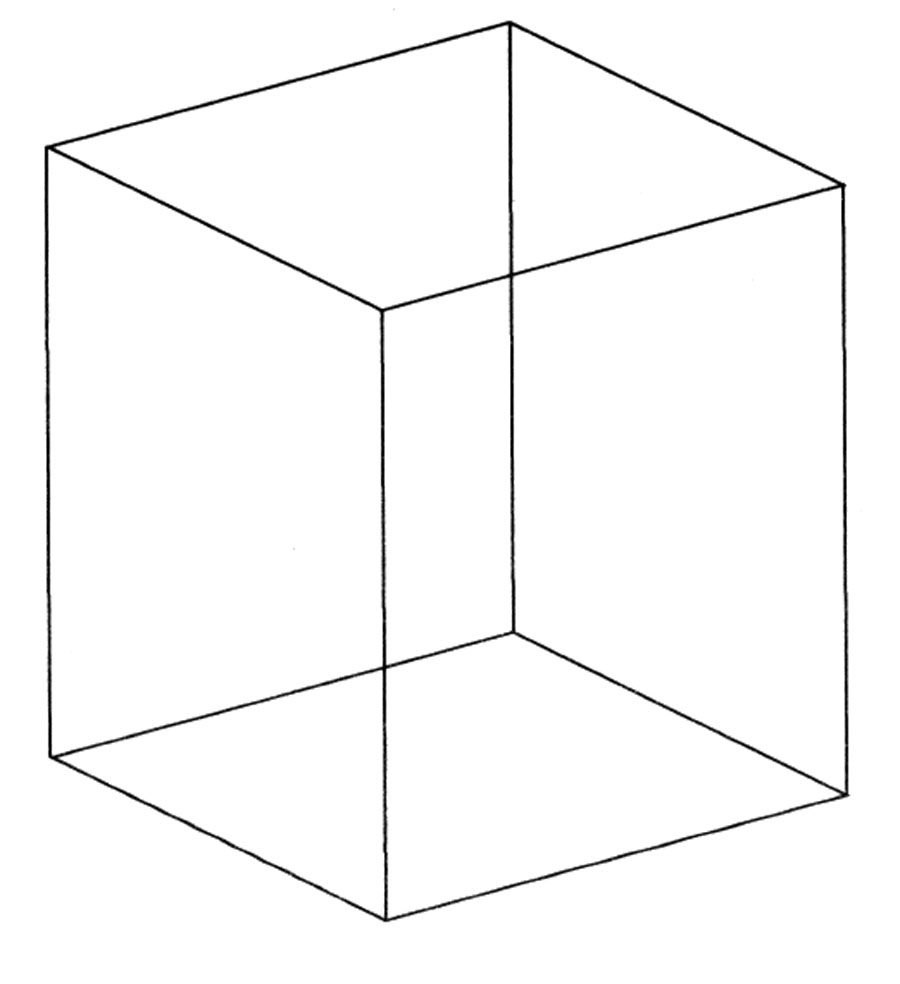
The Necker Cube
The Necker Cube appears to change its orientation in space as you stare at it. This happens because the stimulus can be interpreted in two ways that are equally good or legal from the standpoint of the perceptual system.
Cognitive scientists interpret this as "competing high-level perceptual representations being activated in response to a given visual stimulus" (Suzuki and Peterson, 2000).
To use the language of constraint satisfaction, there are two interpretations of the cube that satisfy all the constraints of the sensory input. That causes the brain to alternate between two equally acceptable interpretations.
If you don't see the two different configurations, just stare at the cube for a while. It will change. If you do see the two different interpretations, experiment with holding the cube in one configuration, resisting the competition from the other interpretation.
Suzuki and Peterson (2000) found substantial effects on this task from intention, which is what most people call willpower. However, even if you rally your intention, eventually the neurons representing one option will fatigue. Then the other representation takes over (the cube flips).
The Necker Cube has eight vertices. Of these eight, six are arrows around the edges, two are forks in the middle. The forks, A and B, determine the viewer's interpretation of the Necker Cube.
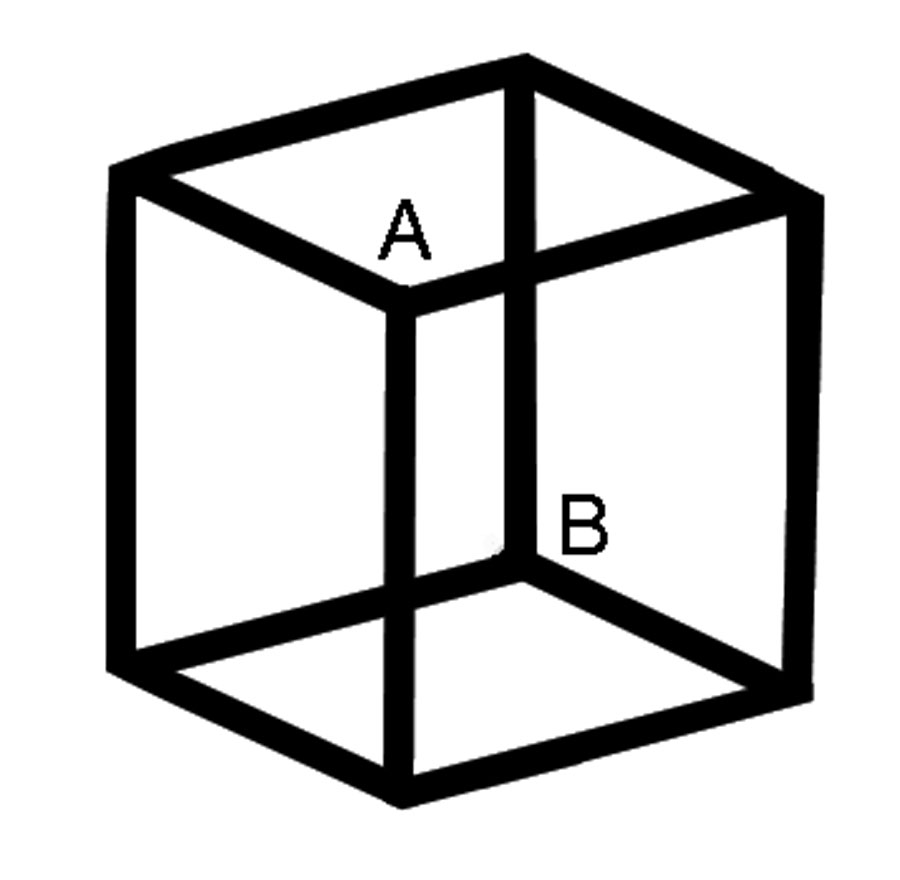
Either A or B appears closer.
If you interpret A as closer to you than B, then A is a "downward pointing outer corner." A marble placed on top of the cube (if the cube was solid) would roll toward you, hence it is a downward corner. If you interpret point A this way, then point B must be an upward pointing inner corner.
This is what is meant by constraint propagation. The interpretation of one element "spreads its influence" or propagates to adjacent elements.
When your neurons get tired of one interpretation, the neurons representing the other interpretation have their chance to become active. When they do, they inhibit the first interpretation (because only one can be active at a time).
The second interpretation would be to interpret point B as an upward-pointing outer corner. That forces a re-interpretation of point A at the same moment.
Note that the cube flips as a whole. The cube is treated as a gestalt or whole thing, and the interpretation of each line and vertex must be consistent with the interpretation of the whole.
Two T-vertices Aligned
Here is another example of constraint propagation. This time it is based on a simple rule: when stems of two T-vertexes (aka vertices) align, they represent a single edge passing behind an object.
That is a computer version of the gestalt law of continuity. The law of continuity, one of the gestalt laws of pragnanz, said segments lining up with each other and extending on both sides of an object are interpreted as the same line.
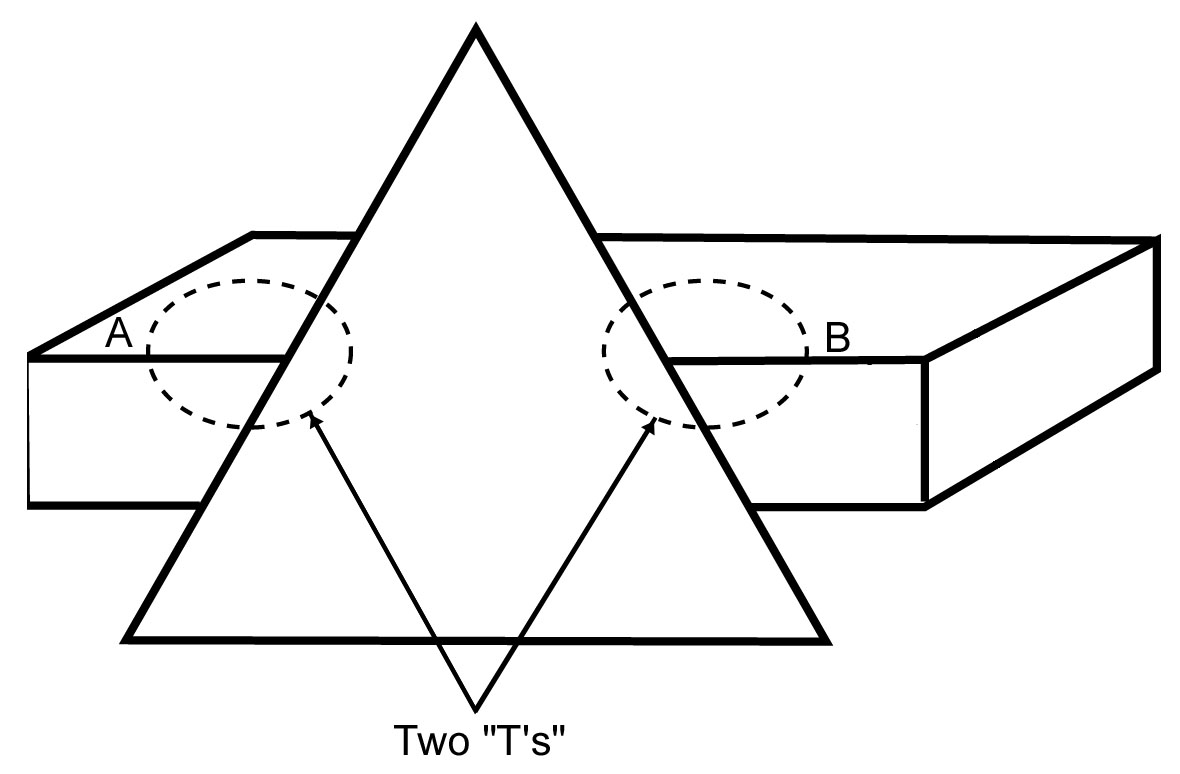
Two T-vertices (circled) with stems (A and B) lined up. A and B are interpreted as the "same line."
In the illustration, two T vertexes are circled and the line segments next to them (the stems of the T) are labeled A and B. The computer is taught to assume, like a human does instinctively, that two T-stems lining up like this are parts of the same edge.
Therefore any identification of segment A will propagate to segment B. If A is identified as an upper, outer edge, then B must be that same thing. (They are the same edge.)
What is a computer version of the gestalt "law of continuity"?
In discussing these examples we have adopted a step-by-step or serial processing approach, directing attention first to one segment, then another. By contrast, the visual system analyzes many different parts of the scene at once. Such parallel processing is much faster and more efficient than serial processing.
How does the brain do visual scene analysis so quickly?
The brain is massively parallel, which helps to explain its quickness in doing things like interpreting scenes. If you tilt your head back with your eyes closed, then open your eyes, your brain receives a new visual pattern, and it interprets all the lines, areas, and vertexes in about a quarter second. That is quite a feat!
Self-driving cars must perform a similar feat. They must identify objects, distinguish cars and pedestrians from other stimuli that might be mere shadows or reflections. This has to be done quickly and continuously.
Part of the solution, again, is to use parallel processing, combining inputs from several detectors and cameras to arrive at the one interpretation of the scene that makes sense of all the incoming data. Only when it has an interpretation of the scene can the car act appropriately to avoid a pedestrian or slow down because of an obstacle.
Top-Down and Bottom-Up Processing
When an interpretation emerges from the data, this is called data-driven or bottom-up processing. Perception must be largely data-driven because it must accurately reflect events in the outside world. You want the interpretation of a scene to be determined mostly by information from the senses, not by expectations.
What is data-driven or bottom-up processing? What is schema-driven or top-down processing?
In many situations, however, your knowledge or expectations will influence perception. This is called schema-driven or top-down processing. A schema is a pattern formed earlier in your experience.
Larger scale or more inclusive concepts are referred to as higher level, while component parts or inputs from the senses are referred to as lower level. Top-down processing occurs any time a higher-level concept influences your interpretation of lower level sensory data.
What is set or expectancy?
Top-down processing is shown by the phenomena of set or expectancy. A classic example is the Rat Man of Bugelski and Alampay (1961).

The "Rat-Man" picture
Subjects saw this picture after viewing earlier slides that showed line drawings of (1) animals, or (2) faces. Depending on whether they saw slides of animals or faces earlier, subjects reported seeing either (1) a rat or (2) a man wearing glasses.
They had been set for one or the other interpretation by the preceding slides. This is a form of top-down processing, in which a schema (a pre-existing concept or pattern) influences the interpretation of incoming data.
In what respect do cartoons rely upon top-down processing?
Comics and cartoons provide many examples of top-down processing. Simple cues are used to suggest complex feelings and emotions.
Cartoonists have a set of conventions for conveying information about mental and physical states. Tiny popping bubbles, for example, show drunkenness.
Movement is shown by lines trailing after an object or little puffs of dust trailing after shoes. Spoken language is shown inside a bubble made out of a continuous line. A silent thought is shown inside a broken line.
A sudden idea may be shown as a lightbulb lighting up over a character's head. Beads of sweat flying off a character show anxiety or physical exertion.
After one gains experience with cartoons, these cues are processed immediately and automatically. One is hardly aware of them.
In general, top-down processing is information processing based on previous knowledge or schemata. It allows us to make inferences: to "perceive" or "know" more than is contained in the data.
Little cartoon droplets do not contain the information that a character is working hard. We add that information based upon our previous experience and knowledge of the conventions of cartooning.
In what sense do we go "beyond the information given"?
Jerome Bruner titled a book about cognitive development Beyond the Information Given (1972) He was acknowledging the pivotal role of inference in cognition.
We go beyond the information given constantly in our mental processes. We learn to add assumptions and supplemental information derived from past experience to the evidence of our senses, and that is how we make sense of the world.
---------------------
References:
Bruner, J. (1973) Beyond the Information Given: Studies in the Psychology of Knowing. New York: Norton.
Bugelski, B. R., & Alampay, D. A., (1961). The role of frequency in developing perceptual sets. Canadian Journal of Psychology, 15, 205-211.
Guzman, A. (1969) Decomposition of a visual scene into three-dimensional bodies. (PhD Dissertation) In A. Grasseli (Ed.) Automatic Interpretation and Classification of Images. New York: Academic Press.
Suzuki S. & Peterson M. A. (2000). Multiplicative effects of intention on the perception of bistable apparent motion. Psychological Science, 11, 202-209.
Waltz, D. (1975) Understanding line drawings of scenes with shadows. Chapter 2 in Winston, P.H. (Ed.) The Psychology of Computer Vision. New York: McGraw-Hill
Write to Dr. Dewey at psywww@gmail.com.
Don't see what you need? Psych Web has over 1,000 pages, so it may be elsewhere on the site. Do a site-specific Google search using the box below.