Copyright © 2007-2018 Russ Dewey

Operational Definitions
To test an idea, one must gather data. This means relating words in a claim to concrete, measurable events in the world. To bridge that gap, scientists need operational definitions. These are definitions that specify how to measure or detect something.
How can one test the claim that 90% of the brain's power is unused? What is one likely to realize, at that point?
Consider the claim that "90% of the brain's power is unused." That is a statement many people seem to take seriously.
The Nobel Prize winning neurophysiologist Sir John Eccles apparently repeated a similar idea in a 1974 lecture at the University of Colorado, although he added, "How can you take a percentage of infinity?" so he was not being literal. Some people think the claim goes back a century to Freud's statement that 90% of the mind is under the surface, unconscious, like 90% of an iceberg.
Even the endorsement of a Nobel Prize winner or famous authority does not make a statement true. To adopt a scientific attitude toward this claim, one must think about how it would be tested.
First one would have to define the terms. What is "the brain's power"? How do you measure it? How do you take a percentage of it?
If you think about how such a claim would be tested, it becomes clear that, in all likelihood, the claim that "90% of the brain is unused" has never been tested. It is just an entertaining idea.
When people say it, they probably mean, "Most people have great untapped potential." A nice discussion of the "ten percent myth" appears here: https://www.csicop.org
To evaluate evidence, one must test ideas. To test ideas, one must gather data. To gather data, one must figure out how to translate the words of a claim into measurement operations.
What problem do scientists face every time they try to evaluate a claim?
In other words, researchers must define each word in a claim by telling what actions or operations measure it. If the words of a claim cannot be defined this way, the claim is meaningless from a scientific perspective. It is just words.
Scientists face this problem every time they try to test an idea. They always must decide how to translate the words of a claim into specific measurement operations.
What is an operational definition?
Scientists attempt to meet this challenge with a special type of definition, the operational definition. This is a definition that specifies how to measure or detect something.
Operational Definitions: Not Always Good
Some students develop a misconception about operational definitions. They think all operational definitions are "good" or scientifically approved. That is not the case!
An operational definition is just a decision about operations to measure something. The decision might be faulty.
What misconception do some students develop, and why is it incorrect?
For example, suppose one wanted to study happiness. To study it, one must measure it.
Perhaps the easiest way to operationalize happiness is to count smiles. This can be done. Happiness can be measured by counting the number of smiles a person emits during an observation period of specified length.
However, counting smiles is a poor operational definition of happiness. That was shown in one study where psychologists from Cornell University analyzed video recordings of bowlers and fans at a hockey game.
They found smiling seldom occurred when people were happy, such as when the home team scored. Instead, people smiled mostly for social reasons, such as when they accidentally bumped into somebody (Rubenstein, 1980).
If counting smiles is not a good operational definition of happiness, what is a good operational definition of happiness? How does one come up with a good measurement procedure, when a psychological process is involved?
This is never an easy question to answer. Happiness or subjective well-being (SWB) is actually the subject of decades of research. Researchers do the best they can, using "life satisfaction" ratings and reports of personal happiness (Diener, Suh, Lucas, & Smith, 1999).
Variables and Values
Throughout this book we will be referring to psychological variables. Some students do not have a grasp of the term variable, so this might be a good time to clarify the concept.
A variable is some characteristic of the world that can vary or change. It is something that can be measured or detected. Therefore operational definitions (which define a word by telling how to measure or detect something) always define a variable.
Variables are distinct from values, which are numbers or scores. Variables can take on many possible values, depending on what is measured.
What are variables? How do they relate to operational definitions? What is the difference between a variable and a value?
The following table shows examples of variables, operational definitions, and values.
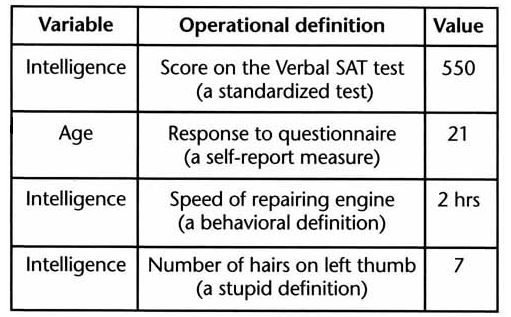
Variables, operational definitions, and values
The last definition in the table (number of hairs on the left thumb) reminds us of the point made above. Operational definitions are not always good or valid. They are simply descriptions of measurement actions.
The last definition is indeed an operational definition, if it implies a set of measurement operations (look at left thumb, count hairs). However, it is a stupid definition if a person wants to measure intelligence.
The first through third definitions are not very good, either. The first equates intelligence with verbal ability as measured by one standardized test. That neglects many forms of intelligence.
The second and third definitions are poorly specified (which questionnaire? what repair?). One cannot assume an operational definition is valid, just because a researcher generates a number with it.
Reliability and Validity
If operational definitions are not always good, how does one distinguish a good one from a bad one? This brings up two basic scientific concepts: reliability and validity.
A good operational definition should be reliable and valid. Here are capsule definitions:
A test is reliable if it produces the same results, again and again, when measuring the same thing.
A test is valid if it measures what you think it measures, as determined by independent ways of measuring the same thing.
One way to measure reliability is to take measurements on two different occasions, making sure you are measuring the same exact thing both times. If you get different results when measuring the same thing on two different occasions, the instrument is unreliable.
What does it mean to say a definition is reliable? Valid?
With a paper and pencil test that uses many items, reliability might be tested using the split-halves method. Odd-numbered items are treated as one test, even-numbered items as another, and the two halves are compared. If they agree, the test is more likely to be reliable.
How does the "split-halves" technique work?
Not every measuring instrument can be divided up this way. Reliability is usually tested using repeated measures: measuring the same thing repeatedly.
With human abilities, it can be difficult to measure the same thing twice. Practice effects occur when a person is exposed to a test or measurement technique.
People change the way they respond to the test, based on their experience taking it the first time. This may or may not be conscious, but it makes repeated measures useless as a reliability check.
In this case, reliability must be assessed by using the same test on many different subjects. Often that is the only way to check psychological tests. Reliability is assessed over a long time period by tracking the dependability of the test.
How do practice effects make reliability testing difficult?
Validity was described as a property that a test possesses if it "measures what you think it measures." How is that determined?
A common sense judgment of validity is that a measurement sounds reasonable on the face of it. That is called face validity. It is just an opinion that a measurement technique sounds good.
Face validity is not very useful to scientists. In fact, it can be a problem, because a test with high face validity may go unchallenged even though it produces misleading results (like equating smiles with happiness, the example used earlier).
Experts on testing list several other types of validity that are more important than face validity. All are variations on the theme of predictive validity. A test or measurement is valid if you can use it to make accurate predictions.
What is face validity? Predictive validity?
For example, an employment test is intended to determine who is suitable for a job. If the test accurately predicts who will remain on the job and receive good evaluations, it has predictive validity.
Self-Report Measures: Notoriously Unreliable
One particular type of operational definition is well known for its lack of reliability: self-report measures. A self-report measure is an operational definition in which a person verbally reports his or her own behavior or mental contents.
Examples of self-report measures are the questions, "How much pain are you feeling on a scale of 1 to 10?" or "Do you dream in color?" or "How many calories did you eat yesterday?" Most people will agree to answer such questions, but the results are not dependable. In fact, self-report measures are notoriously inaccurate and unreliable.
Retrospective self-reports are the least accurate type. They ask a person to look back in time to remember details of earlier behaviors or experiences.
An example is asking people what foods they ate the previous day. This is a retrospective self-report. It combines the uncertainty of self-report with the uncertainty of memory reconstruction.
One problem with retrospective self-reports is that people may add or subtract details. But errors can be larger than this. When people are asked to recall incidents from earlier in life, even people trying very hard to tell the truth cannot necessarily distinguish between a creative fabrication and a genuine memory.
The problem is that each memory is a fresh creation, and it usually feels accurate whether it is or not. We will see evidence for this in at least three different places in this book: in the study of hypnosis, the study of memory, and the study of eyewitness testimony.
What is wrong with self-report measures? What is the least accurate type?
In graduate school, my professors discussed the inaccuracy of retrospective self-report data. However, the truth did not come alive for me until I was doing research on student learning for my PhD thesis.
In one study, I asked students to estimate (to the nearest half hour) the amount of time they spent studying the previous week's chapter. All my students agreed to answer this question.
Nobody said "I don't remember" or "I cannot make that estimate." Assuming the information was accurate, I prepared to use it in my research.
Then I lost some of the questionnaires. No problem: the students cheerfully filled out identical, duplicate questionnaires.
A day later I found the original questionnaires, so I compared to two sets to see how the data compared. To my shock, the estimates of study time were completely different!
A student who put "4 hours" on the first questionnaire might put "1 1/2 hours" on the second. These two answers came from the same student, asked about the same chapter (the previous week's assignment) on two successive days.
I was dismayed, but it was a valuable lesson. My operational definition of study time, using the student's retrospective self-report, was clearly unreliable.
Therefore it was not valid either. It was not measuring what I thought it measured. Answers on one day did not even predict the answers on the next day.
If one must use self-report data, they should always be labeled as such. (The word "they" is used here because the word data is plural; datum is the singular form.)
What should one always do, if using self-report data?
For example, a person asking people whether they are happy is gathering self-report data. The researcher should caution readers by labeling this data as self-reported happiness.
This approach is used, for example, to deal with the problem of measuring happiness. Researchers commonly use self-report data labeled as such, or they use the term subjective well being. The word subjective means this is a self-report.
---------------------
References:
Diener, E., Suh, E. M., Lucas, R. E., & Smith, H. E. (1999). Subjective well-being: Three decades of progress. Psychological Bulletin, 125, 276-302.
Rubenstein, C (1980, February). When you're smiling. Psychology Today, p.18.
Write to Dr. Dewey at psywww@gmail.com.
Don't see what you need? Psych Web has over 1,000 pages, so it may be elsewhere on the site. Do a site-specific Google search using the box below.